La cache di Google è qualcosa che, almeno di nome, dovreste aver già incontrato tutti, almeno una volta. E il motivo è molto semplice. Sotto al risultato di ogni ricerca su Google, infatti, accanto alla scritta "Pagine simili" compare anche "Copia cache": probabilmente non ci avrete mai fatto caso, o forse l'avete ignorata, ma quella parola è finita sotto i vostri occhi già centinaia di volte.
Ma che cos'è questa cache? Vediamo di spiegarlo in breve.
La cache è un archivio, nel quale sono conservate copie di altri documenti. Tutti i programmi con cui ci colleghiamo a internet, cioè i browser come Internet Explorer, Firefox e Chrome, ne hanno una e la usano per conservare una copia di tutte le pagine che visitiamo: in questo modo, se torniamo a un sito già visitato in precedenza, il browser potrà sfruttare la copia nella cache per caricarlo più velocemente. A noi, però, non interessa la cache dei browser, almeno oggi, per cui possiamo procedere oltre e arrivare alla cache di Google.
Google utilizza la propria cache per archiviare una copia di tutte le pagine presenti nel suo indice: la cache è quindi un archivio di tutti i documenti che Google è in grado di cercare. Il funzionamento è piuttosto semplice. Google al momento è il principale motore di ricerca della Rete; per poter cercare, però, ha bisogno prima di tutto di conoscere il contenuto della Rete: i nomi dei siti presenti, il contenuto delle loro pagine e così via. Per ottenere queste informazioni, Google utilizza alcuni programmi automatici, i bot (detti anche "ragni", per ovvia analogia con il Web), che eseguono un "censimento" della Rete: saltando da una pagina all'altra, ne copiano il contenuto e lo inoltrano a Google stesso. Una volta arrivato a destinazione, il contenuto delle pagine è indicizzato, ossia è catalogato nell'archivio di Google in base a elementi come argomento, parole chiave e così via. Quando noi eseguiamo una ricerca, Google sfoglia il contenuto del suo archivio e ci restituisce le pagine che più si avvicinano a ciò che noi staimo cercando, in base alle informazioni in suo possesso.
La cache è appunto l'archivio di Google, ossia il "luogo" in cui sono salvate le copie di tutte le pagine internet che ha indicizzato.
Questo archivo è aggiornato periodicamente, in modo da aver sempre sotto controllo tutto ciò che è pubblicato in Rete. Naturalmente, data la vastità della Rete, non sarebbe possibile controllare e aggiornare ogni ora il contenuto di tutti i siti, perché le pagine da controllare sono miliardi. Per questo motivo, i bot di Google controllano e aggiornano il contenuto degli archivi secondo un criterio abbastanza sensato: la frequenza degli aggiornamenti dipenderà dalla dimensione del sito, dal numero di visite che riceve, dalla quantità di nuove pagine che quel sito produce, eccetera. I siti più grandi, famosi e attivi saranno dunque visitati più spesso dai bot; i siti più piccoli e meno attivi, invece, saranno visitati di meno.
Per ogni pagina indicizzata da Google, la cache conterrà l'ultima versione che è stata copiata dai bot: più o essere dunque più o meno recente, a seconda di quanto spesso i bot visitano quel determinato sito. Talvolta la copia della cache è identica all'originale, talvolta invece la copia della cache è più vecchia dell'originale, se l'originale è stato modificato o aggiornato dopo l'ultimo passaggio dei bot. Guardando la copia cache di una pagina, dunque, potremo trovare o una versione identica di quella pagina, oppure una versione più vecchia. Questo cosa significa? Significa che, per esempio, se una certa informazione è stata rimossa dalla pagina originale di un sito, nella copia cache potrebbe invece esserci ancora, perché magari i bot di Google non hanno ancora avuto il tempo di aggiornarla. Ed è un dettaglio che non va trascurato, perché ci ricorda che in Rete nulla è mai distrutto per sempre.
La cache di Google ha però anche altri aspetti, che possono tornarci utili. Un aspetto lo abbiamo già visto: se qualche informazione è stata cancellata dalla pagina originale, potrebbe ancora esistere nella sua copia cache. Su scala più ampia, ci può permettere di recuperare le pagine di un sito che, nel frattempo, è stato rimosso dalla Rete: se Google lo aveva indicizzato, per un certo periodo potremo ancora accedere alla sua copia cache, anche se il sito è ormai defunto. Ancora: se un filtro web non è stato progettato con cura, possiamo aggirarlo usando la cache di Google, in modo del tutto lecito. E il motivo è semplice. Se un filtro ci impedisce di accedere al sito "pincopallino", noi possiamo raggiungerlo lo stesso visitando la copia conservata nella cache di Google: in questo caso, noi non stiamo accedendo al sito pincopallino, ma stiamo accedendo a Google, perché la copia si trova appunto negli archivi di Google. Non è proprio come usare un proxy, d'accordo, ma è una possibilità da tenere presente. Eccetera eccetera.
Come accedere alla copia cache di un sito? Beh, il sistema più semplice è quello di cliccare "copia cache", che troviamo in coda a ogni risultato di una nostra ricerca su Google. In alternativa, possiamo cercare direttamente la copia cache su Google: basta digitare cache: seguito dall'indirizzo del sito che ci interessa. Nella copia cache di una pagina, inoltre, è sempre indicata la data dell'ultimo aggiornamento: potremo così sapere subito a quando risale quella copia.
Magazine Informatica
Potrebbero interessarti anche :
Possono interessarti anche questi articoli :
-
Facebook punta sui video e ci mostra quelli che più ci piacciono

La scorsa settimana avevamo riportato i risultati di una interessante analisi che dimostrava come Facebook sta battendo YouTube, la piattaforma video per... Leggere il seguito
Da Franzrusso
INTERNET, MEDIA E COMUNICAZIONE, TECNOLOGIA, TELEFONIA MOBILE -
Microsoft potrebbe sostituire Windows Phone con Android? [RUMOR]
![Microsoft potrebbe sostituire Windows Phone Android? [RUMOR]](https://m22.paperblog.com/i/289/2897678/microsoft-potrebbe-sostituire-windows-phone-c-L-fT9C0B-175x130.jpeg)
Recentemente sono molti gli indizi che possono farci immaginare una certa “confidenza” tra Microsoft e Google, come ad esempio il supporto di app Android su... Leggere il seguito
Da Enjoyphone
INFORMATICA, TECNOLOGIA -
MXIII Tv Box Android: Come trasformare il TV di casa in una smartTV
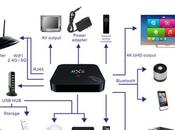
Come abbiamo visto recentemente, le SmartTV o TV “intelligenti” stanno andando molto forte, non solo per l’effettiva comodità che portano in dote ma anche per... Leggere il seguito
Da Enjoyphone
INFORMATICA, TECNOLOGIA -
Che cosa è PEGI Google Play

Che cosa Significa PEGI su Google PLay e a che cosa serve - La classificazione della App visualizzata sul Play store di Google Da qualche tempo, sul Google Play... Leggere il seguito
Da Allmobileworld
INFORMATICA, INTERNET, TECNOLOGIA -
È un uccello? È un aereo? No, è un porcospino - Recensione - iPhone

Il leggendario Sonic Team si cimenta con il genere degli endless runner sui dispositivi mobile I primi episodi di Sonic per Mega Drive sono stati un vero e... Leggere il seguito
Da Intrattenimento
TECNOLOGIA, VIDEOGIOCHI -
WhatsApp per Android: aggiunte le nuove emoji [DOWNLOAD]
![WhatsApp Android: aggiunte nuove emoji [DOWNLOAD]](https://m2.paperblog.com/i/289/2897680/whatsapp-per-android-aggiunte-le-nuove-emoji--L-sa8DOg-175x130.png)
L’avvento delle nuove emoji che ha caratterizzato l’aggiornamento ad iOS 8.3, ha portato nell’applicazione di messaggistica una ventata di novità solamente per ... Leggere il seguito
Da Enjoyphone
INFORMATICA, TECNOLOGIA

Magazines
LA COMMUNITY INFORMATICA

TOP UTENTI
-
 allmobileworld
allmobileworld
8820742 pt -
 videogiochi
videogiochi
3205714 pt -
 Riccardo Conti
Riccardo Conti
2069489 pt -
 intrattenimento
intrattenimento
1608418 pt
I GIOCHI SU PAPERBLOG
-
 Pacman
Pacman
Pac-Man é un video gioco creato nel 1979 da Toru...... Gioca -
 Nostradamus
Nostradamus
Nostradamus è un gioco " shoot them up" con una...... Gioca -
 Magical Cat Adventure
Magical Cat Adventure
Riscopri Magical Cat Adventure, un gioco d'arcade...... Gioca -
 Snake
Snake
Snake è un videogioco presente in molti...... Gioca